Model development
Understanding AI for maritime data applications
Data is the foundation of ML models. High-quality and large volumes of data are crucial for creating effective models.
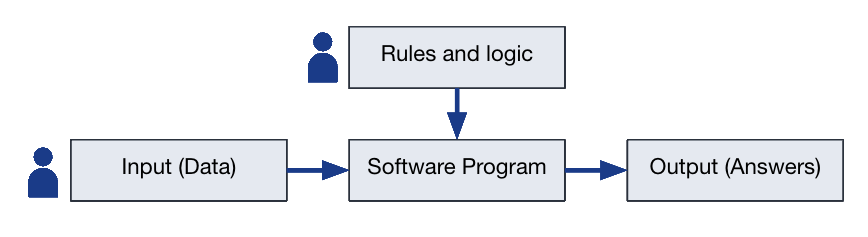
Software Program vs. Machine Learning
Software Program: Relies on rules and logic explicitly programmed by humans. For example, a rule might state that temperatures above 20°C are "warm" and below 20°C are "cool." The software follows these rules to make decisions.
Machine Learning: Instead of a human creating rules, ML models learn from data pairs of inputs and outputs. For instance, an ML model learns what "warm" and "cool" mean by analyzing temperature data and corresponding labels provided by humans (12°C=warm, 21°C=cold, 19°C=warm, etc). This learning process allows the model to provide answers about new data without predefined rules.
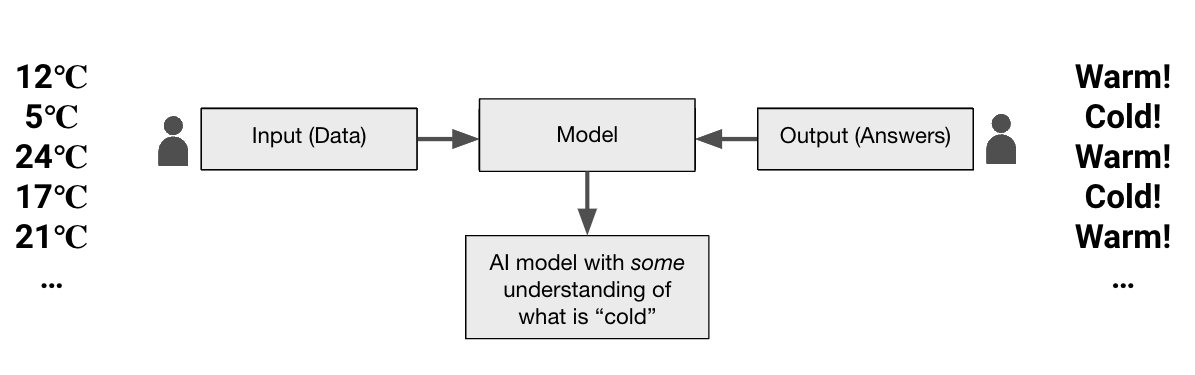
This example is an oversimplification to illustrate how a machine learning model learns. ML becomes more useful with big data and more complex tasks.
To make the above example about weather more suited using ML, we could add data about wind speed, season, time of day, humidity, geography, etc. Then, the model can evaluate more complex situations (e.g., 21 degrees, 3 km/h wind, autumn, 42% humidity, Southern Mexico, 1000m elevation) to better assess whether such conditions would likely feel warm or cold.
Another version of AI model development, common with Large Language Models, like ChatGPT, is a process called self-supervised learning.
Model development
Now that you’re familiar with how ML works, let’s take a closer look at the steps involved to develop a ML model.
The below diagram shows simplified steps to developing a ML model.

As an example, let's explore how a ML is developed for detecting fishing behavior using the steps from the above diagram.
Problem Statement: Identify when a vessel is fishing.
Data Selection/Gathering: Data should resemble what a human would use to do this same task. For fishing, we would want to gather data such as:
- AIS data (Position, vessel)
- Bathymetry
- Knowledge about different fishing methods
- Weather conditions
- Time of day
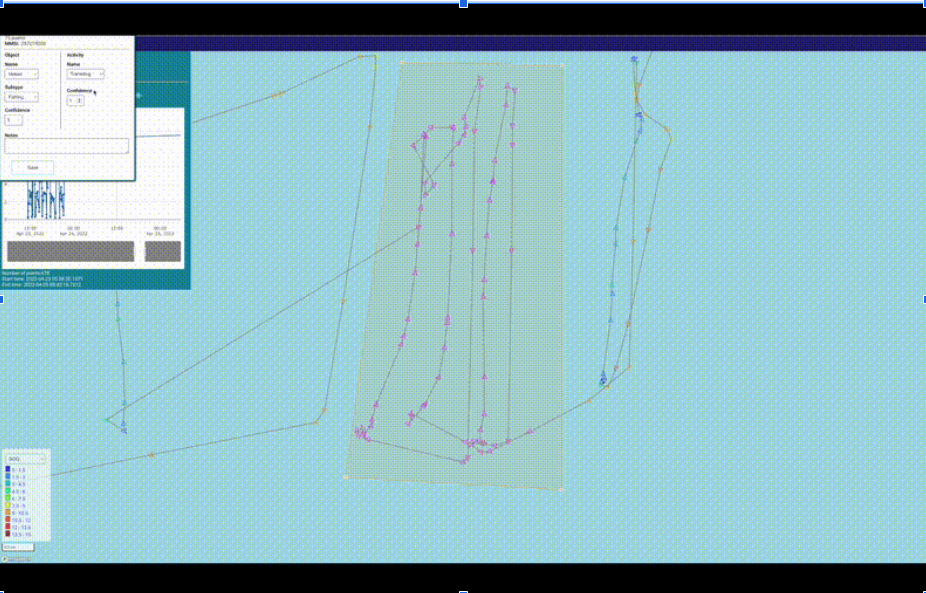
Labeling/Annotating: Annotators label data to teach the model what fishing behavior looks like.
In the image, we can see that an annotator is labeling a certain section of AIS vessel tracks as “fishing” behavior. The annotator also has access to helpful data, like bathymetry, time of day, etc. to increase confidence.
Training: The labeled data (training data) is fed into the model to learn fishing patterns from the human-annotated examples.
To have a sense of “how much” data a model may use, theSkylight team is labeling 10,000 months of vessel history to detect various types of behavior like fishing.
Evaluation: Assess the model's accuracy in detecting fishing behavior.
[In the next section, we'll look closer at evaluation, which involves measuring precision (correct fishing detections) and recall (all actual fishing events detected). The result of the evaluation is an F1 score. An F1 score is a balance of precision and recall to evaluate performance.]
At this stage, developers can decide whether to release the model. If the model is not performing well enough, the developers can adjust the precision and recall of the model, gather and annotate more data and retrain the model until it meets satisfactory performance.
Model Deployment/Feedback: Deploy the model for real-world use and gather feedback. Real-world feedback can be used as training data to update and improve the model.
As the diagram indicates, development of ML models aren’t necessarily linear, but instead follow key steps toward achieving a high quality model to address the needs of the problem statement.
Was this article helpful?